icql-blog
分布式基础_分布式缓存
一、经典缓存模式
1. Cache Aside Pattern 旁路缓存模式
数据以数据库中的数据为准,缓存中的数据是按需加载的。适用于一致性要求较高的场景
读数据:命中缓存直接返回,没有命中缓存则主动查询数据库更新缓存后再返回
写数据:更新数据库后删除缓存(事务内删除缓存)
存在并发问题导致数据不一致:
>A线程读到旧数据,挂起
>B线程写完新数据,删除缓存
>A线程拿到旧数据再次写入到缓存
2. Read/Write Through Pattern 读写穿透模式
外部只与缓存组件交互,以缓存中的数据为准,缓存组件和数据库交互。不常使用
读数据:命中缓存直接返回,没有命中缓存则由缓存组件查询数据库更新缓存后再返回
写数据:先读缓存,命中缓存先更新缓存,再由缓存组件去同步更新数据库,没有命中缓存则由缓存组件直接更新数据库
3. Write Back Caching Pattern 异步写回模式
外部只与缓存组件交互,和2中不同的点在域异步更新数据库。适合提高写性能,但会丢数据
二、常见缓存问题
1. 穿透
请求不存在的key,缓存没有命中,大量请求落在db
解决方案:
(1)提前校验入参,避免无效数据 (2)查到不存在的数据时,往缓存写一份为空的数据(适用于数据较少的情况,如共享数据) (3)布隆过滤器,不存在则一定不存在,存在则有可能不存在,过滤大量无效请求(适用于数据较多的情况,如用户维度的缓存)
2. 雪崩
短时间内大量key过期,大量请求落在db
解决方案:
(1)缓存失效时间不要设置在同一时间,常发生在和 “天” 有关的缓存
3. 击穿
热点key过期后,瞬间大量请求落在db
解决方案:
(1)实际读库的时候,采用(本地锁+双重检测)控制查询流量 (2)热点key设置失效时间为晚上凌晨的流量低峰
4. 大key
缓存的数据过大,占用
进行数据切割分多份存储(推荐),或者压缩数据
三、实践
根据场景选择合适的缓存策略
1. 短时间数据一致性要求较低,最终一致即可
1) 适用场景
所有用户共享的数据,数量较少,例如投放计划、活动配置等
2) 缓存策略
定期刷新适当的数据到缓存中,只读缓存
3) 实践示例
(1) 典型表结构:
id,startTime,endTime,state
(2) 需要定期缓存的数据:即将开始的数据 + 正在进行的数据 + 刚刚结束的数据
startTime <= (当前时间 + x天) and endTime >= (当前时间 - x天)
过期时间:x天
(3) 使用时再进行有效状态过滤
startTime <= now and endTime >= now and state = 有效
(4) 缓存模型
本地短期缓存(一级缓存,二级缓存回源)
redis缓存(二级缓存,定期刷新)
本地长期缓存(降级缓存,定期刷新)
(5) 异常告警
2. 数据一致性要求较高
1) 适用场景
用户个人数据,数量巨大等
2) 缓存策略
采用 cache aside 模式
3) 实践示例
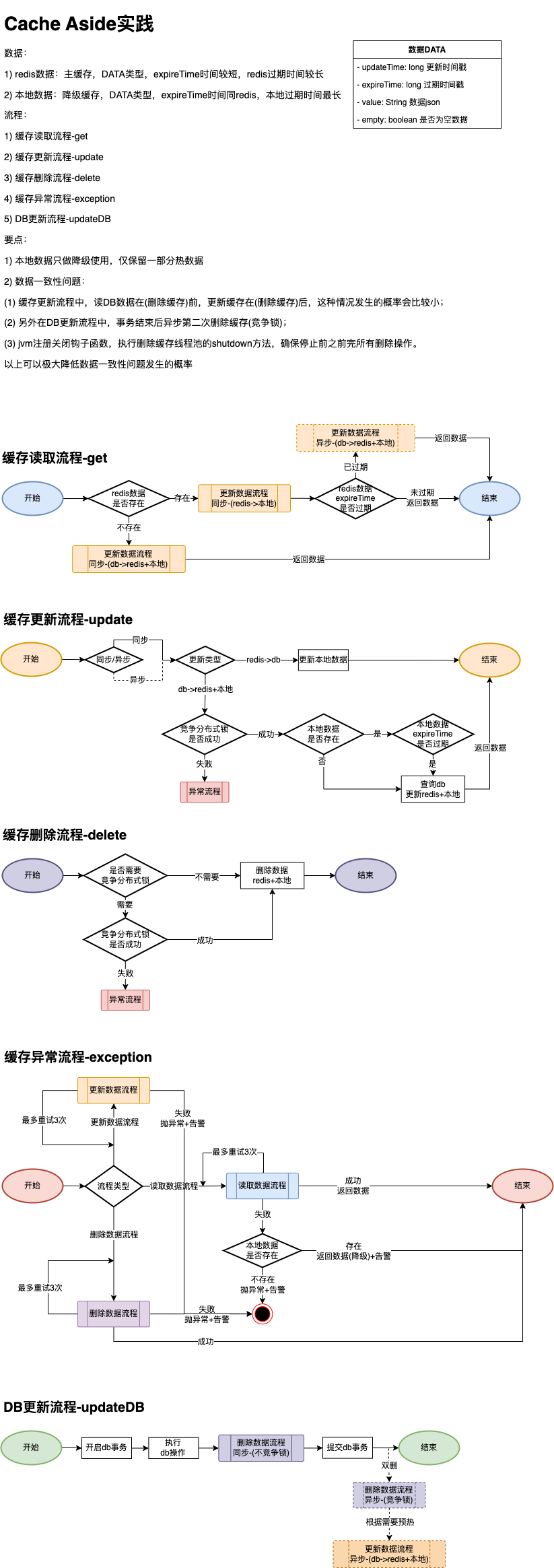
3. 常用缓存框架
java-jetcache
https://github.com/alibaba/jetcache
<dependency>
<groupId>com.alicp.jetcache</groupId>
<artifactId>jetcache-starter-redis</artifactId>
<version>${jetcache.latest.version}</version>
</dependency>